深層学習を使ったモデルの学習について、例を示しながら説明をしていきます。
なお、このページは、Intro to Deep Learningを参考にしていますので、より詳細を見たい方はリンクをご覧ください。
データの読み込み
まず、赤ワインのデータセット(DL Course Data)のcsvファイルで読み込み、訓練データとテストデータに分割します。
次に、データはバラバラな値をとると訓練時にうまくいかないことが知られているので、0から1の値をとるように標準化しましょう。
最後に、ターゲットとなるqualityの値を訓練データからdropすることで、データの準備は完成となります。
import pandas as pd
from IPython.display import display
red_wine = pd.read_csv(dirPos + 'dl-course-data/red-wine.csv')
# Create training and validation splits
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
display(df_train.head(4))
# Scale to [0, 1]
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
# Split features and target
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']モデル作成
データの準備が終わったら、今後はどのようなモデルを用いるのか、決めていきます。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)学習の実行
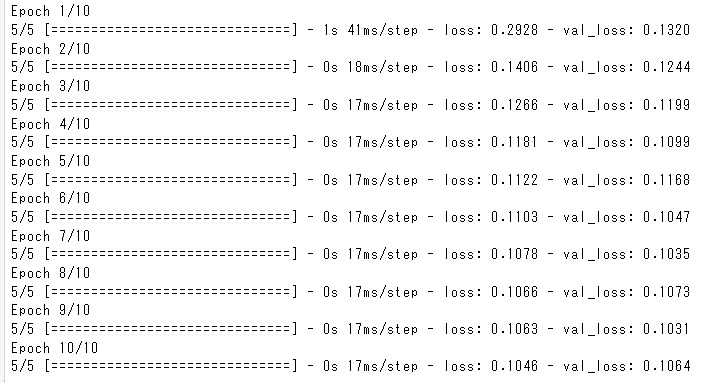
作成したmodelに、訓練データとテストデータを入れ、損失関数が小さくなるように学習を進めます。
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=10,
)