概要
CNNやRNNを使わずに、Attentionのみを使ったニューラルネットワークが、2017年に論文にて提案され、そのモデルの名前をTransformerと言います。
Transformerは、自然言語処理(NLP)のタスクにおいて非常に効果的なニューラルネットワークモデルです。2017年にGoogleの研究者によって提案され、その後のNLPの多くのタスクで革新的な成果を上げました。
従来のNLPモデルでは、系列データ(テキストなど)を処理するためにリカレントニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)が使用されてきましたが、Transformerはこれらのモデルとは異なるアーキテクチャを持っています。
Transformerは、セルフアテンション(Self-Attention)と呼ばれる機構を中心に構築されています。セルフアテンションは、入力の異なる位置間の依存関係を捉えるための仕組みであり、入力の全ての位置に対して重み付けされた注目度(Attention)を計算します。これにより、文中の単語の間の長距離の依存関係をモデルが学習できます。
Transformerの主な特徴は以下の通りです:
- セルフアテンション機構:各位置の単語の関連性を考慮し、文全体の文脈情報を学習するための仕組み。
- マルチヘッドアテンション:複数のセルフアテンションヘッドを使用し、異なる表現を学習することで性能を向上させる手法。
- 位置エンコーディング:単語の位置情報を考慮するための特殊な埋め込み手法。
- トランスフォーマーブロック:セルフアテンション層とフィードフォワードニューラルネットワーク層から構成される基本的なユニット。
Transformerは、機械翻訳、文書要約、質問応答、感情分析など、さまざまなNLPタスクにおいて高い性能を発揮しました。その直感的なモデルアーキテクチャとパラレル処理の可能性により、長文や大規模なデータセットの処理においても優れた効果を示しています。
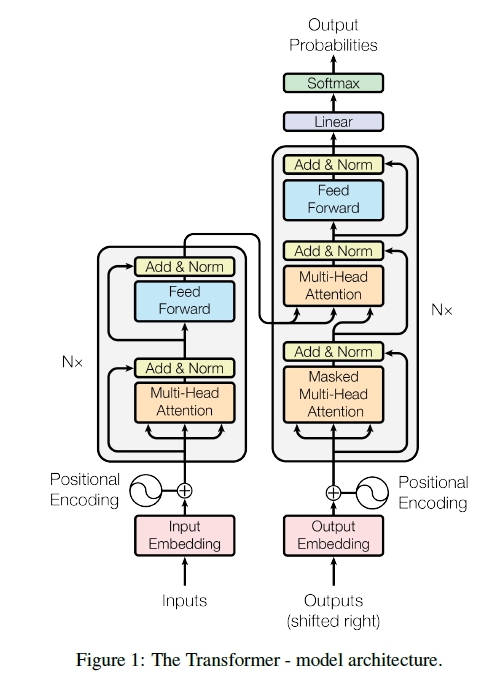
Transformerは、Encoder-Decoder型のモデルとなっており、上図の左側がエンコード、右側がデコードをする流れを示しています。
使用するメリット
翻訳などを目的として回帰型ニューラルネットワーク(RNN)が用いられてきましたが、RNNの欠点として並列計算ができないという点があります。RNNは、逐次的に計算を行うので、並列計算を行えるような計算環境であっても、その計算資源を生かせません。そこで、RNNは並列計算ができない欠点を補うために、RNNの代わりにAttentionを使った機構であるTransformerが提案されました。
また、RNN/CNNでは、学習を行う際に、近傍の情報しか活用できないので、全体を踏まえた学習を行うことが難しい面がありました。Transformerでは、Attentionを利用することにより、全体的な情報を活用することに成功しています。
基本的な構造
CNNやRNNを用いずに、Attentionを使用したモデルです。
Embedding層では、ある単語を線形空間上の1点に割り当てことをします。これを分散表現と言います。各単語ごとに値が割り振られています。
Positional Encodingでは、情報の順序をエンコードする機構となっています。ここで、翻訳であれば、各単語の順番を学習したり、画像認識では、各ピクセルの位置を学習します。
Multi-Head Attention
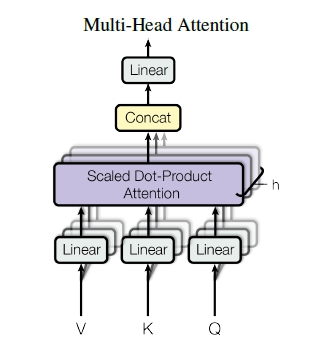
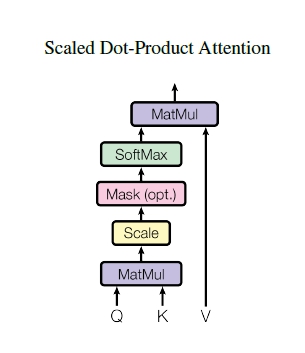
Scale-DotProduct Attentionでは、クエリとキーの類似度からバリューがどの値に注意するべきか計算を行います。
コード例
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerEncoder, self).__init__()
self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = keras.Sequential([layers.Dense(ff_dim, activation="relu"), layers.Dense(embed_dim),])
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
class Transformer(keras.Model):
def __init__(self, num_layers, embed_dim, num_heads, ff_dim, input_vocab_size, target_vocab_size, rate=0.1):
super(Transformer, self).__init__()
self.embedding = layers.Embedding(input_vocab_size, embed_dim)
self.encoder = [TransformerEncoder(embed_dim, num_heads, ff_dim, rate) for _ in range(num_layers)]
self.dense = layers.Dense(target_vocab_size)
def call(self, inputs, training):
x = self.embedding(inputs)
for encoder in self.encoder:
x = encoder(x, training)
output = self.dense(x)
return output
このコード例では、Transformerモデルのエンコーダ部分を実装しています。TransformerEncoderクラスは、Transformerモデルの1つのエンコーダ層を表します。Transformerクラスは、指定したエンコーダの数だけエンコーダ層を重ねたTransformerモデルを表します。
上記のコードは、TensorFlowのlayersモジュールを使用していくつかの層を定義しています。セルフアテンション(MultiHeadAttention)、フィードフォワードニューラルネットワーク(Dense)、およびレイヤー正規化(LayerNormalization)が含まれています。
このコード例では、Transformerモデルのエンコーダ部分のみが示されていますが、デコーダ部分や他の必要なコンポーネント(位置エンコーディング、マスキングなど)も含めた完全なTransformerモデルの実装にはさらなるコードが必要です。