概要
日本語の自然言語処理は以下の順に行われます。
- テキストへの前処理
- 形態素解析
- 構文解析
- 意味解析
- 文脈解析
まずは、それぞれについて解説します。
- テキストへの前処理
- ノイズ除去
入力として用いるテキストデータには、HTMLのタグが入っていたり、テキストとは無関係なデータが混入している場合があります。このようなノイズを除去します。 - 表記ゆれの統一
ひらがなとカタカナ、半角と全角などの表記ゆれに対する処理を行います。 - ストップワード除去
「です」「ます」など、さまざまな文章に登場し、文の意味にあまり影響を与えないような単語を除去します。
- ノイズ除去
- 形態素解析
意味を持つ最小の単位のことを形態素と呼びます。形態素解析は、文を形態素で区切る作業のことを指します。例えば、「私は日本語の勉強をしています。」という文章があったときに、次のように解析します。
私/は/日本語/の/勉強/を/して/います/。
「私」は名詞、「は」は助詞、「日本語」は名詞、「の」は助詞、「勉強」は名詞、「を」は助詞、「して」は動詞、「います」は助動詞、「。」は句点というように解析されます。日本語では、単語間に明確な区切りがないために、形態素解析が重要になります。形態素ごとに区切られた後は、辞書を用いて品詞などの言語情報を加えます。精度よく形態素解析を行うために、様々なツールが使用されており、代表的なツールとしては、MeCab(和布蕉)などが挙げられます。
以下では、使用例を示します。
まずは、必要なライブラリをインストールします。
pip install mecab-python3
pip install unidic-lite先ほどの「私は日本語の勉強をしています。」をMecabを使って、解析してみます。
import MeCab
sample_text = '私は日本語の勉強をしています。'
text = MeCab.Tagger("-Owakati")
output = text.parse(sample_text)
print(output)このコードをPython環境で実行すると以下の結果が得られ、形態素ごとに解析出来ていることが確認できます。
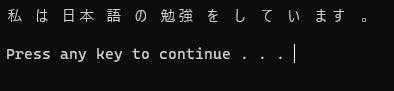
Taggerの引数をなくしてTagger()とすると、より詳細を表示することが出来ます。
import MeCab
sample_text = '私は日本語の勉強をしています。'
text = MeCab.Tagger()
output = text.parse(sample_text)
print(output)
- 構文解析
構文解析とは、文の中にある形態素の関係を分析する手法のことです。文中の単語やフレーズの関係を理解し、木構造などの形で表現します。
例えば、「彼女は、庭で美しい花を育てています。」という文を構文解析すると以下のような構造に解析されます。
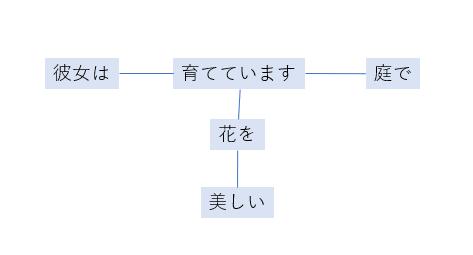
この構文木によって、文を構造として扱うことが可能になり、主語や述語、修飾語などの各品詞の関係を理解しやすくなります。コンピュータで文脈を把握するうえで、この構文解析の処理は重要な役割を担っています。